
The Problem Was Simple
By late 2022, our Platform X support team was handling ~60 tickets every two weeks. The frustrating part was that most tickets did not require human intervention.
Looking at 20 weeks of data (categories):
- 47 responses: Just links to our documentation
- 64 tickets: “How do I access Azure DevOps?”
- 39 tickets: Platform panel access issues
- 22 tickets: Security alerts needing the same wiki reference
Over those 20 weeks, this added up to nearly 700 tickets, most of them repeating questions already answered in our documentation.
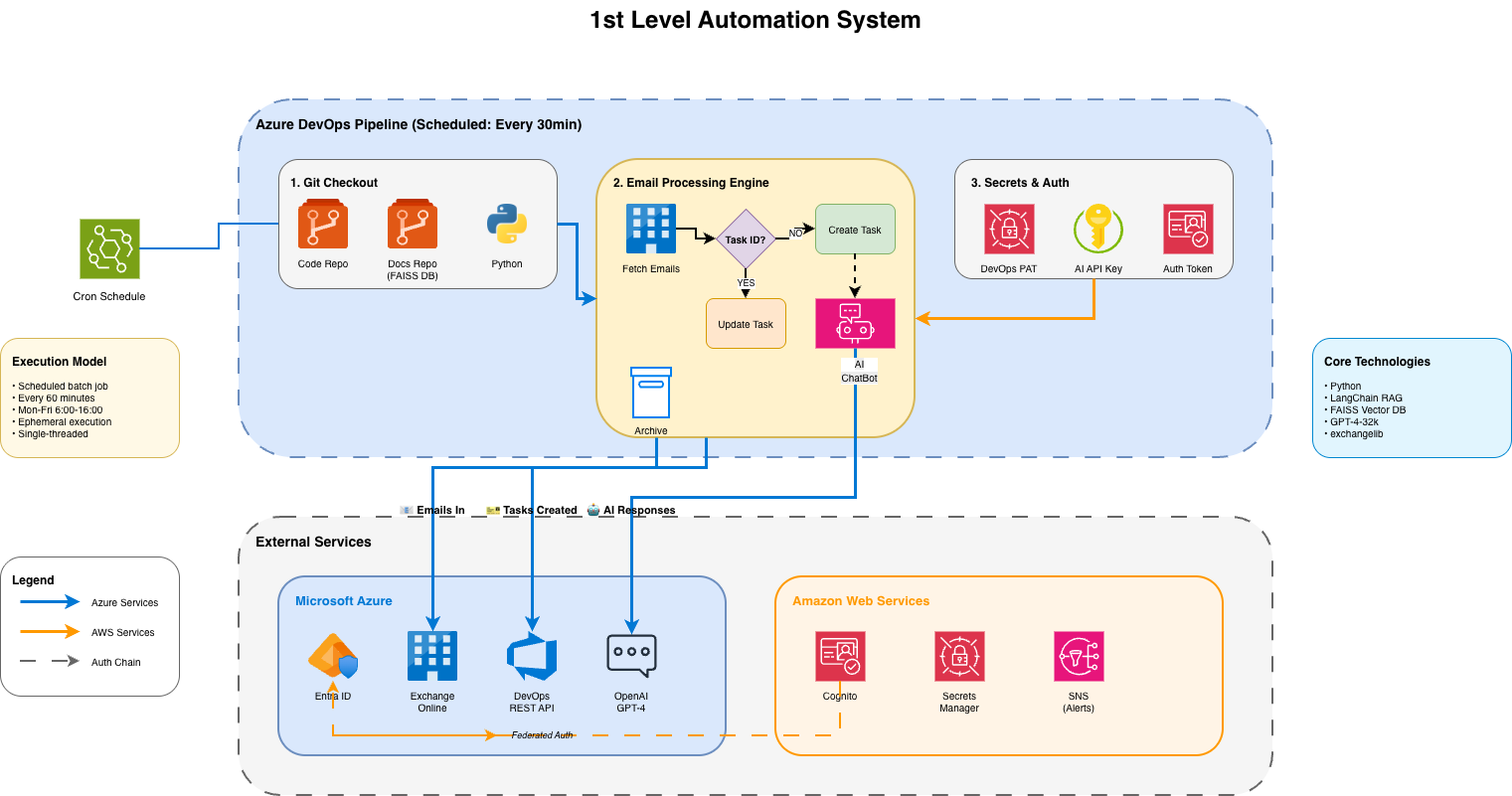
Why Users Weren’t Finding Answers
We had comprehensive internal documentation. The problem wasn’t missing information, it was findability. Users would:
- Hit an issue
- Email support instead of searching docs
- Wait for us to… send them a documentation link
We weren’t solving novel problems. We were human search engines.
The Solution: RAG, Not Just Prompts
When GPT-3.5 dropped in November 2022, we started experimenting. By January 2023, we had a plan.
Why RAG?
All our platform knowledge was documented internally. We did not need a model to invent answers. We needed a system that could reliably retrieve and reference what was already written.
RAG gave us:
- Grounded responses from actual docs
- Citations to specific pages
- Ability to update knowledge without retraining
- Answers we could audit and trust
Straight prompting couldn’t do this reliably. We needed retrieval.
Processing Workflows
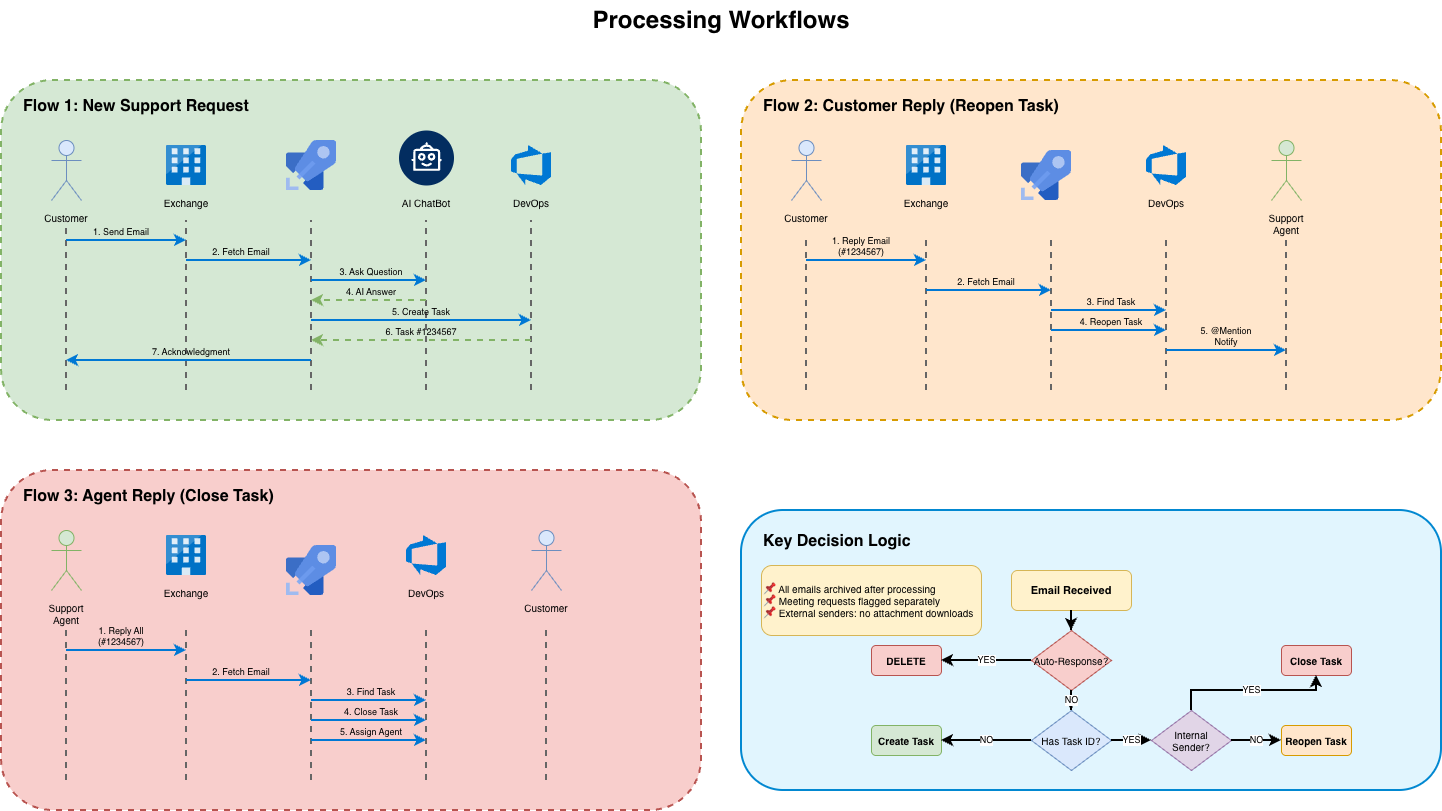
The Technical Challenge Nobody Expected
Data residency
We needed to feed our internal documentation to Azure OpenAI. In early 2023, the only available Azure OpenAI region was Sweden.
This triggered internal compliance discussions:
- Can we send internal docs to a Swedish data center?
- What’s our data classification?
- Who approves this?
The technical implementation was straightforward. The organizational clearance took weeks.
The Results
- First-level tickets effectively eliminated
- Support team focuses on actual platform improvements
- Users get instant responses with doc links
- Complex issues properly escalated to second-level
The breakdown of what got automated:
- 64 tickets: User access issues → Auto-response with sync procedures
- 47 tickets: General questions → Direct documentation links
- 14 tickets: Re-sending invitation emails → Automated workflow
- 11 tickets: User synchronization → Automated resolution
The pattern was clear: repetitive, documented processes could be handled without human intervention.
What We Learned
1. Documentation quality matters more with RAG
Bad docs produce bad AI responses. This forced us to improve our documentation, a beneficial side effect.
2. Being first meant building trust slowly
We were the first team in our organization to deploy AI-powered support automation. Stakeholders needed proof:
- Start with low-risk ticket categories
- Show the AI’s work (citations)
- Keep humans in the loop initially
We didn’t eliminate our support team. We freed them to work on platform improvements instead of repetitive answers.
3. Privacy/compliance
Technical implementation: 2 weeks. Getting data residency approval: Longer.
Why Early Adoption Mattered
January 2023 feels like ancient history in AI-time. But being first in our organization meant:
- No internal playbooks to copy
- Learning by doing
- Building organizational knowledge about AI deployment
We weren’t chasing hype (wasn’t that much back then), we had a concrete problem, existing documentation, and suddenly, a tool that could connect them.
The Bigger Picture
This wasn’t about replacing support teams with AI. It was about respect for everyone’s time:
- Users get instant answers
- Support engineers solve real problems
- Documentation becomes the source of truth
The technology enabled this. But the real win was organizational: we proved that comprehensive documentation + smart retrieval > hiring more people to manually search that documentation.
Conclusion
The best AI projects don’t start with “let’s use AI.”
They start with “we have this problem” and end with “AI happened to be the right tool.”